1.3.3 Statistische Auswertung
Die statistische Auswertung der Analysenwerte für die Proben vom Jebel Tawiga und aus dem Gedaref-Gebiet erfolgte mit Hilfe der Faktoren- und Clusteranalyse und zum Teil mit Hilfe der multiplen Diskriminanzanalyse. Für die Kaoline der übrigen Vorkommen wurden diese Methoden aufgrund der relativ geringen Probenanzahl nicht durchgeführt.
Die Faktorenanalyse verfolgt generell das Ziel, aus einer Vielzahl von Variablen eine möglichst begrenzte Anzahl von "Hintergrundvariablen", also voneinander unabhängigen Einflussgrößen, zu bestimmen (BACKHAUS et al. 1990). Dabei wird nicht die gesamte Varianz der Variablen erfasst, sondern nur der Teil, der den Variablen gemeinsam ist. Ähnlich wie bei der Clusteranalyse geben die einzelnen Faktoren eine Abhängigkeit innerhalb einer Gruppe wieder, die zu interpretieren ist.
Um die Faktorenanalyse durchführen zu können, mussten zunächst sämtliche Daten logarithmiert werden, um zu annähernd normalverteilten Datensätzen zu gelangen. Die Variablen wurden anschließend auf analytische Ausreißer überprüft und die betreffenden Proben eliminiert. Elemente, die in der RF-Analyse nahe der Nachweisgrenze lagen bzw. schlecht reproduzierbar sind, wie z.B. Mo, Pr, Rb, La, Th, U, und Cu, wurden ebenfalls ausgeschlossen. Im Zuge der Analyse erfolgte eine Anti-Image-Korrelation, die als ein Maß für die Angemessenheit der Stichprobe gilt und für jede einzelne Variable als MSA-Wert ("measure of sampling adequacy") berechnet wird. Variablen mit MSA-Werten unterhalb 0,6 wurden zusätzlich ausgeschlossen, so dass sich die Variablenanzahl auf letztendlich 17 bzw. 20 Variablen reduzierte. Auch das ermittelte Kaiser-Meyer-Olkin-Maß (KMO), ein zusammenfassendes Maß für die Eignung des Faktorenmodells, mit einem Wert von 0,8 für beide Probenpopulationen zeigt, dass die Variablenauswahl für die Faktorenanalyse gut geeignet ist (KAISER 1974). BROSIUS (1989a,b) und BACKHAUS et al. (1990) empfehlen, die Variablen in sogenannte standardisierte Variablen, auch Z-Variablen genannt, zu überführen, die immer einen Mittelwert von 0 und eine Standardabweichung von 1 aufweisen. Dies dient dem Zweck, unterschiedliche Konzentrationsmaße wie Prozent und ppm vergleichbar zu machen. Die Berechnung der Faktoren basiert auf der standardisierten, Z-transformierten Korrelationsmatrix (R-Modus) (DAVIS 1986). Bei der Faktorenanalyse sind Kommunalität und Eigenwert zentrale Begriffe. Die Kommunalität gibt an, welcher Teil der Streuung einer Variablen durch alle im Modell berücksichtigten Faktoren erklärt wird (BROSIUS 1989b), der Eigenwert hingegen, welcher Teil der Gesamtstreuung aller Variablen durch einen bestimmten Faktor erklärt wird.
Für die Ermittlung der Faktorenanzahl stehen zwei häufig verwendete Kriterien zur Verfügung. Nach dem Kaiser-Kriterium ist die Zahl der zu extrahierenden Faktoren gleich der Zahl der Faktoren mit Eigenwerten größer eins. Der sogenannte "scree-Test" ordnet die Eigenwerte in abnehmender Reihenfolge (Abb. 3 und 4). An die auslaufende Kurve wird eine Gerade angepasst. Der letzte Punkt links auf der Geraden liefert theoretisch die Anzahl der zu extrahierenden Faktoren. Diese Methode ist nicht immer eindeutig, da die Anpassung der Geraden nicht einheitlich definiert ist (BACKHAUS et al. 1990). Eigenwerte unter 1 werden durch das Programm SPSS/PC+ automatisch in Anwendung des Kaiser-Kriteriums ausgeschlossen (NORUSIS 1988), da jede Variable mit sich selbst verglichen durch die Z-Transformation eine Streuung von 1 aufweist.

Abb. 3: Scree-Test für standardisierte Datenmatrix
(Proben Jebel Tawiga, n = 127).
Nach dem Kaiser-Kriterium werden 4 Faktoren extrahiert.
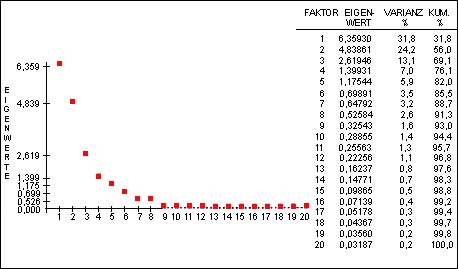
Abb. 4: Scree-Test für standardisierte Datenmatrix
(Proben Gedaref, n = 113).
Nach dem Kaiser-Kriterium werden 5 Faktoren extrahiert.
Die ermittelten Faktoren werden als absolute Größe in der Faktorladungsmatrix in Relation zu den einzelnen Variablen gesetzt. Lädt eine Variable hoch auf einen Faktor, so bildet der Koeffizient (Faktorladung) eine Maß für die Bedeutung oder Zugehörigkeit der Variablen zum Faktor.
Die Clusteranalyse kann als geeignetes Hilfsmittel, ergänzend oder alternativ zur Faktorenanalyse, für die Klassifikation und Interpretation geochemischer Daten z.B. von Bauxiten verwendet werden (BARDOSSY 1992). Das Prinzip der Clusteranalyse basiert auf der Zusammenfassung von in sich homogenen Einzelfällen (Stichproben) zu einem Cluster (Gruppe von Fällen), die sich im Vergleich zu anderen Clustern deutlich unterscheiden. Die Ähnlichkeit der Fälle bildet somit das entscheidende Kriterium für deren Zusammenfassung (BROSIUS 1989b). Als Maß für die Ähnlichkeit bzw. Unähnlichkeit der Fälle dient die "quadrierte Euklidische Distanz". Sie errechnet sich aus der Summe der quadrierten Differenzen zwischen den Variablenwerten zweier Fälle. Das Distanzmaß kann sich, abhängig von der Dimension der Variablen, beträchtlich in der Größenordnung unterscheiden. Aus diesem Grunde werden die Werte mit einem Faktor multipliziert, um sie in einem Bereich absoluter Werte von 0 bis 25 darstellen zu können. Dies entspricht dem relativen Clusterabstand (rescaled distance) (NORUSIS 1988). BERGS (1981) und BACKHAUS et al. (1990) empfehlen als Fusionierungsalgorithmus die Ward Methode, da sie in den meisten Fällen sehr gute Partitionen findet und die Elemente richtig den Gruppen zuordnet.
Die Methode der Multiplen Diskriminanzanalyse (MDA) dient allgemein dazu, Daten mehrerer Gruppen auf ihre Ähnlichkeiten bzw. Unähnlichkeiten zu überprüfen. Durch die MDA werden die Unterschiede zwischen den Gruppen maximiert, die Variationen innerhalb einer Gruppe hingegen minimiert (LE MAITRE 1992).
Im Rahmen dieser Arbeit wird die MDA dazu genutzt, die geochemischen Unterschiede der jeweiligen Lateritproben aus dem Gebiet des Jebel Tawiga zu bestimmen und eine Zuordnung zu den nur teilweise aufgeschlossenen Ausgangsgesteinen zu treffen (vgl. SIAD 1994). Ziel ist es, für das gesamte Untersuchungsgebiet die Ausgangsgesteine zu rekonstruieren und in Form einer abgedeckten geologischen Karte darzustellen (vgl. Kap.3.1.3).
Um eine Trennung der verschiedenen Ausgangsgesteinsgruppen zu erreichen, muss im Zuge der MDA überprüft werden, ob die Unterschiede zwischen den Gruppen rein zufällig oder signifikant sind. Für die Beurteilung dieses Sachverhaltes stehen u.a. Gütemaße wie der Chi-Quadrat-Test oder die Wilks`Lambda-Werte zur Verfügung. Hierbei wird zunächst die "Nullhypothese" aufgestellt, d.h. es wird angenommen, dass die wirkliche Differenz Null ist und die gefundenen Differenzen rein zufällig von Null abweichen (SACHS 1968). Werden im Chi-Quadrat-Test hohe Werte ermittelt, liegt die Vermutung nahe, dass ein signifikanter Unterschied besteht. In Abhängigkeit von den Freiheitsgraden sind hohe Chi-Quadrat-Werte somit Ausdruck für die Signifikanz, so dass die Nullhypothese zurückgewiesen werden kann. Die Wilks`Lambda-Werte sind ein Maß für die Streuung der Funktionswerte innerhalb der Gruppen. Je mehr sich diese Werte Null annähern, um so besser ist die Trennfunktion (BROSIUS 1989b).